Recommended by:

Top 20 UK science resources,
The Tutor Website
Recommended by:

Rated:

2010
Listed on the science, engineering and technology section of

'providing you with access to the very best Web resources for education and research, evaluated and selected by a network of subject specialists.'
(Please note that intute closed in July 2011)
Section 3: Organic
CHAPTER 25:
BIOCHEMISTRY
NB This chapter has now been
updated to improve browser compatibility.
Please
use the 'send email' link at the top right hand corner of this page to
report any problems.
25.1. INTRODUCTION
There are four main categories of macromolecule which may come to mind as the components of living organisms:
 Proteins
Proteins
fats
carbohydrates
nucleic
acids
They also occur in combination:
a
nucleoprotein = nucleic acid plus protein
a
glycoprotein = carbohydrate plus protein etc.
Moreover, macromolecules may have inorganic groups bonded to them, as in:
phospholipids.
In this chapter we shall look at the four major groups of macromolecule and the smaller molecules from which they are built.
25.2. PROTEINS, POLYPEPTIDES, PEPTIDES AND AMINO ACIDS
25.2.1. Amino acids are the building blocks from which proteins are made. There are just over 20 naturally occurring amino acids ranging from the simplest, 2-aminoethanoic acid (trivial name, glycine) to more complex molecules, some with two amino groups (lysine), some with two acid groups (aspartic acid) and others with inorganic groups, or even containing ring structures.
All naturally occurring amino acids are a-amino acids with the general formula:
....NH2............. (amino group
attached to carbon 2, the 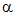 -carbon)
-carbon)
....|
R-CH-COOH
Most can be synthesised in the body from other substrates (a biochemical word for reactants which react at the active site of an enzyme), though some cannot. Those that cannot are called essential amino acids because they are an essential part of the diet. The list of essential amino acids varies from species to species.
25.2.2. Synthesis
of -amino
acids can be
acheived in two ways. What reactions do you know that have the
potential for producing an amino group and a carboxyl group on the same
carbon atom, possibly via intermediate stages?
i)................. NH4Cl/KCN................................
HCl
....CH3CHO.........![]() .........
CH3CH(NH2)CN.........
.........
CH3CH(NH2)CN.........![]() .........
CH3CH(NH2)COOH
.........
CH3CH(NH2)COOH
.....................................
................................H2O
ii)....................... Cl2..................................
NH3
....CH3COOH.........![]() .........
CH2ClCOOH.........
.........
CH2ClCOOH.........![]() .........
CH2(NH2)COOH
.........
CH2(NH2)COOH
25.2.3. Some general properties.
i) It can be seen from
the structure of -amino
acids that carbon atom 2 is asymmetric (section 24.3.3.) and that each
amino acid will therefore have two optically active forms. Naturally
occurring amino acids are all laevorotatory (-) isomers.
ii) Since they possess both an amino group and a carboxylic acid group, amino acids show the properties of both classes of compound. However, since one group is acidic and the other basic, they also form internal salts known, for some bizarre reason, as zwitterions:
..............NH2............................ +NH3
............./..................................../
.........R-CH............. .............
R-CH
.............
R-CH
.............\....................................\
..............COOH........................... COO-
They are therefore neither particularly acidic nor particularly basic. Other properties which they share with salts are: they are crystalline solids with high melting points, and they are more soluble in water than in most organic solvents.
In aqueous solution the maximum concentration of zwitterion occurs at a pH which is specific for each amino acid. The particular pH is known as the isoelectric point of the amino acid. When an amino acid solution is electrolysed at this pH, the amino acid does not move to either electrode.
Amino acids with an equal number of amino groups and acid groups are known as "neutral" amino acids, those with more amino groups than acid groups are known as basic amino acids, and those with more acid groups than amino groups are known as acidic amino acids.
25.2.4. Another
property of amino acids is the basis of protein synthesis. It
is the formation of the peptide link. The reaction,
which is essentially the formation of a substituted amide (section
22.3.6.iii), occurs in living organisms at the active site of an enzyme:
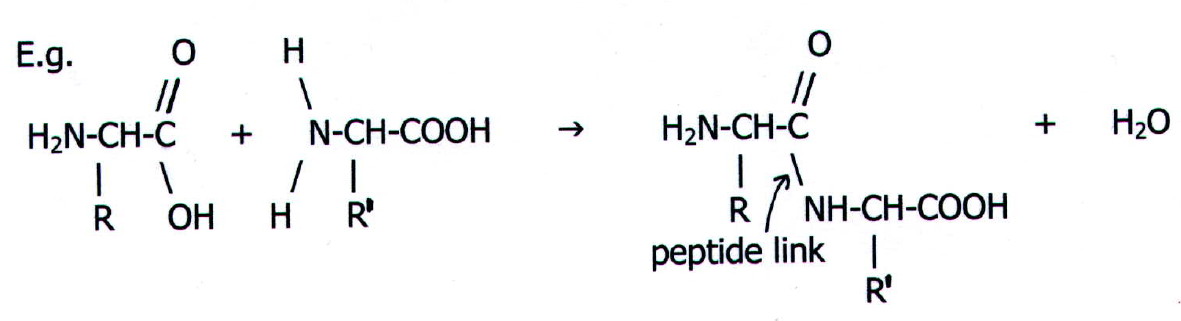
The result is a dipeptide.
Further substitution of amino acids into the chain produces
tripeptides, tetrapeptides etc. otherwise known simply as peptides.
Eventually peptides reach a respectable enough size to be called polypeptides
or even proteins.
Note that it is conventional to write the N-terminal end of peptides, polypeptides, and proteins on the left hand side of the page.
25.2.5. Size is not the only determining difference between a polypeptide and a protein. The dividing point is set at about 10,000 RMM, but smaller peptide chains may be classified as proteins, and larger ones as polypeptides.
Other factors which favour classification as a protein are:
i) A natural source as opposed to a synthetic source. Note, however, that some hormones are quite small polypeptides.
ii) A high degree of secondary, tertiary (and quarternary) structure.
Primary structure is the amino acid sequence. Every protein (e.g. an enzyme like chymotrypsin, a hormone like insulin, or a cell membrane protein) has a unique amino acid sequence.
It is the amino acid
sequence of a protein which determines its properties. Changing just
one amino acid in the sequence of hundreds making up an enzyme, may
make the enzyme totally useless. The reason can be seen by looking at
part of the sequence in a hypothetical protein molecule:

Each of the R groups in the long
chain has a profound effect on the protein's secondary and tertiary
structure (see below). Moreover, a particular R group may, for example,
play a key role at the active site of an enzyme.
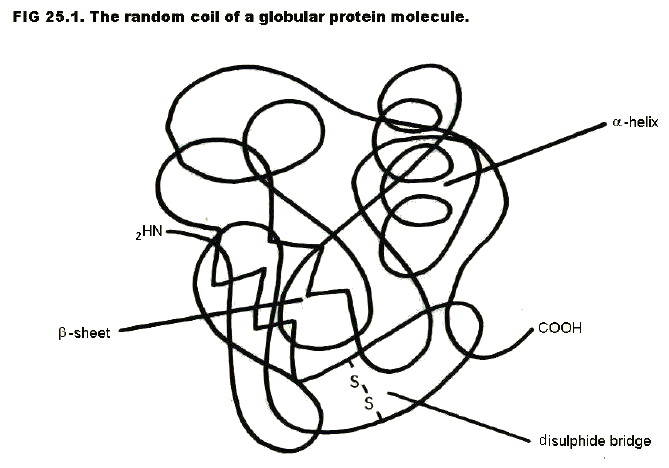
Secondary
structure includes regions of so called  -helix,
and
-helix,
and 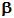 -sheet,
where regions of the chain are held in definite conformations,
largely by hydrogen bonding between adjacent groups on the chain. The
hydrogen bonding will clearly depend on the sequence of amino acids
and, hence, side chains.
-sheet,
where regions of the chain are held in definite conformations,
largely by hydrogen bonding between adjacent groups on the chain. The
hydrogen bonding will clearly depend on the sequence of amino acids
and, hence, side chains.
Tertiary structure is further folding and coiling of the chain in a way unique to each protein, and again dependent on the sequence of amino acids and, hence, side chains.
The bonding in tertiary structure may be hydrogen bonding between a carboxyl group on one R group and an amino or hydroxyl group on another R group. Van der Waals bonding is also involved. In addition, disulphide bridges may form between sulphur-containing R groups:
................................ ....oxidation
.........-SH.... +....
HS-.........![]() .........
-S-S-
.........
-S-S-
Disulphide bridges are particularly important in the protein which constitutes hair and finger nails (keratin). The technique of perming relies on temporary breaking of the bridges by reduction, and re-forming them in new positions.
Keratin is an example of a fibrillar protein in which the peptide chain lies along the axis of the fibre. Other examples occur in muscles and tendons.
Other proteins are globular.
Examples include enzymes, hormones, cell membrane proteins and egg
white albumin. Globular proteins are often soluble.
As well as intra-molecular
bonding, tertiary structure is also determined by bonding of groups on
the outside of the protein molecule with surrounding molecules and
ions. The surrounding molecules may be water in the case of soluble
proteins, or other macromolecules. It may even be both: some cell
membrane proteins are partly embedded in cell membrane lipids (fats)
and partly exposed to aqueous solutions inside and/or outside the cell.
In the case of soluble proteins, the pH and ionic strength of the solution will have a profound effect on structure and solubility, since they will determine the state of functional groups on the R groups.
For example, the pH will determine whether acid groups and amino groups are dissociated or not. Changing the pH may cause a protein chain to unfold, a process known as denaturation. When a protein denatures it usually precipitates out of solution. A well-observed example of a protein denaturing is the frying of an egg. In this case heat causes egg white albumin to denature and come out of solution.
Increasing the ionic strength of a solution may also cause proteins to precipitate, a process known as salting out.
Quarternary structure refers to the association between separate polypeptide chains. Haemoglobin, for example, is a globular protein made up of four separate chains. Hydrogen bonds and van der Waals bonding are responsible for the associations, which are just as specific as those in tertiary structure.
25.2.6. The hydrolysis of proteins produces a mixture of smaller polypeptides, peptides, and/or amino acids, depending whether the hydrolysis is partial or complete.
Hydrolysis breaks the peptide (amide) link:
.......................................dilute
acid
E.g.....
/\/\/\/NHCO\/\/\/\.........![]() .........
/\/\/\/NH3+.... +....
HOOC\/\/\/\
.........
/\/\/\/NH3+.... +....
HOOC\/\/\/\
25.2.7. Complete hydrolysis can be brought about
chemically, using mineral acids, or biochemically, using certain
proteolytic enzymes.
i) Chemically: To avoid damage to the side chains, a method used for chemical hydrolysis is: heating with concentrated hydrochloric acid for 48 hours, in a sealed evacuated test tube, at 110°C in an oven. The evacuation is necessary to prevent oxidation of some side chains by air.
ii) Enzymatically: Some enzymes break off amino acids one at a time, starting at one end of the chain. The longer the treatment, the more extensive the hydrolysis. These enzymes can be used to determine the sequence of amino acids in a protein (protein sequencing), a process which has to large extent been superceded by DNA sequencing of the genes which determine the structure of proteins (section 25.5).
25.2.8. Partial hydrolysis can also be brought about chemically or biochemically.
i) Chemically: Heating with dilute hydrochloric acid will cause partial hydrolysis. The result will be a random mixture of polypeptides, peptides, and amino acids. The more vigorous the treatment, the smaller the products i.e. the more extensive the hydrolysis.
In contrast, treating with CNBr, produces very specific polypeptides and peptides, because this reactant hydrolyses the peptide link only between certain pairs of amino acid residues.
ii) Enzymatically: In contrast with the enzymes used for complete hydrolysis, other proteolytic enzymes hydrolyse proteins only at specific sites, between specific pairs of amino acid residues. The particular pairs vary from one proteolytic enzyme to another. As with CNBr, this produces a very specific mixture of polypeptides and peptides. These enzymes (and CNBr) may be used to break larger proteins into smaller fragments which are easier to sequence.
25.2.9. Separating mixtures of proteins, polypeptides, peptides, and amino acids.
Biochemists spend a lot of time isolating particular proteins etc. from naturally occurring mixtures such as blood plasma, or cell homogenates. Separating mixtures produced by hydrolysis is a less common pastime now that protein sequencing has been largely replaced by DNA sequencing.
Two common methods for separating mixtures in aqueous solution are:
i)
precipitation, often the first method applied to crude mixtures such as
blood plasma.
ii)
chromatography.
25.2.10. Precipitation: The notes on tertiary structure in section 25.2.5. indicated that careful choice of pH and/or ionic strength will cause precipitation of very specific proteins and polypeptides. If the mixture is then centrifuged, the desired protein(s)/polypeptide(s) may be found in either the residue or the supernatant. The residue can be redissolved if necessary.
Resolution may be increased by repeating the process on either the supernatant liquid, or the redissolved precipitate, and choosing a new pH and/or ionic strength.
25.2.11. Chromatography has already been discussed in section 23.2.7. It may be a first step in isolating a protein, or it may be carried out on one of the solutions resulting from the precipitation method.
Gel-filtration, affinity chromatography, and ion-exchange chromatography are commonly used to separate protein and polypeptide mixtures. The affinity groups and the ion-exchange groups are usually bonded to beads of gel-filtration polysaccharides, so two simultaneous types of chromatography will occur in each of these cases.
25.3. FATS AND OILS (LIPIDS)
25.3.1. The fats and oils which occur in living organisms are esters of long chain carboxylic (fatty) acids with propan-1,2,3-triol (glycerol). Their roles include storage (adipose tissue in animals, and oils in plants, especially in their seeds), and structure (cell membranes).
The length of the carboxylic acid chain varies, depending on the source.
| TABLE 25.1. Carboxylic acids from commonly occurring fats and oils | ||
| Source fat/oil | carboxylic acid | acid chain length |
| laurel, coconut, & palm oil, milk, etc. | dodecanoic (lauric) acid | 12 |
| most animal & vegetable fats incl. palm oil & milk | hexadecanoic (palmitic) | 16 |
| most animal & vegetable fats, esp. hard fats e.g. beef | octadecanoic (stearic) | 18 |
| olive oil | cis-octadec-9-enoic (oleic) | 18 |
Unsaturated carboxylic acids are most common in vegetable oils. Such oils can be hardened for use in margarines by catalytic hydrogenation of the double bonds (section 21.3.4.). However, medical studies suggest that a low proportion of saturated fats in margarine is desirable for health reasons.
Moreover, there are some unsaturated carboxylic acids which are essential in the diet for healthy growth (essential fatty acids). Adults do not tend to develop symptoms due to a lack of essential fatty acids, but babies fed on skimmed milk with a low fat content sometimes develop eczema.
25.3.2. Hydrolysis of fats and oils produces the alcohol and the carboxylic acids (or their salts, depending on conditions). The acids can be obtained by hydrolysing natural fats with superheated steam - hexadecanoic acid is the first to distil over. The salts are obtained by alkaline hydrolysis.
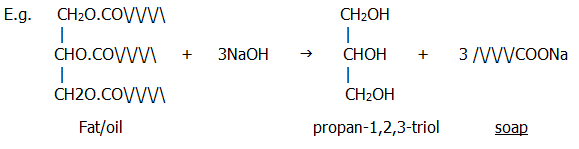
Note that the sodium and potassium salts of long chain carboxylic acids are soaps. The action of soaps and detergents is dealt with in the next chapter (section 26.6.2.)
25.4. CARBOHYDRATES: approximate general formula: (CH2O)n
25.4.1. Carbohydrate molecules can be:
i) large (e.g.
cellulose found as the main structural element in plant cell walls,
starch used for storage in plants, and glycogen used for storage in
animals),
or
ii) relatively small (mono- and disaccharides),
though
iii) never simple.
25.4.2. The
complexity of even a monosaccharide is demonstrated by the
number of diagrams which can be used to represent one of the best known
monosaccharides, glucose:
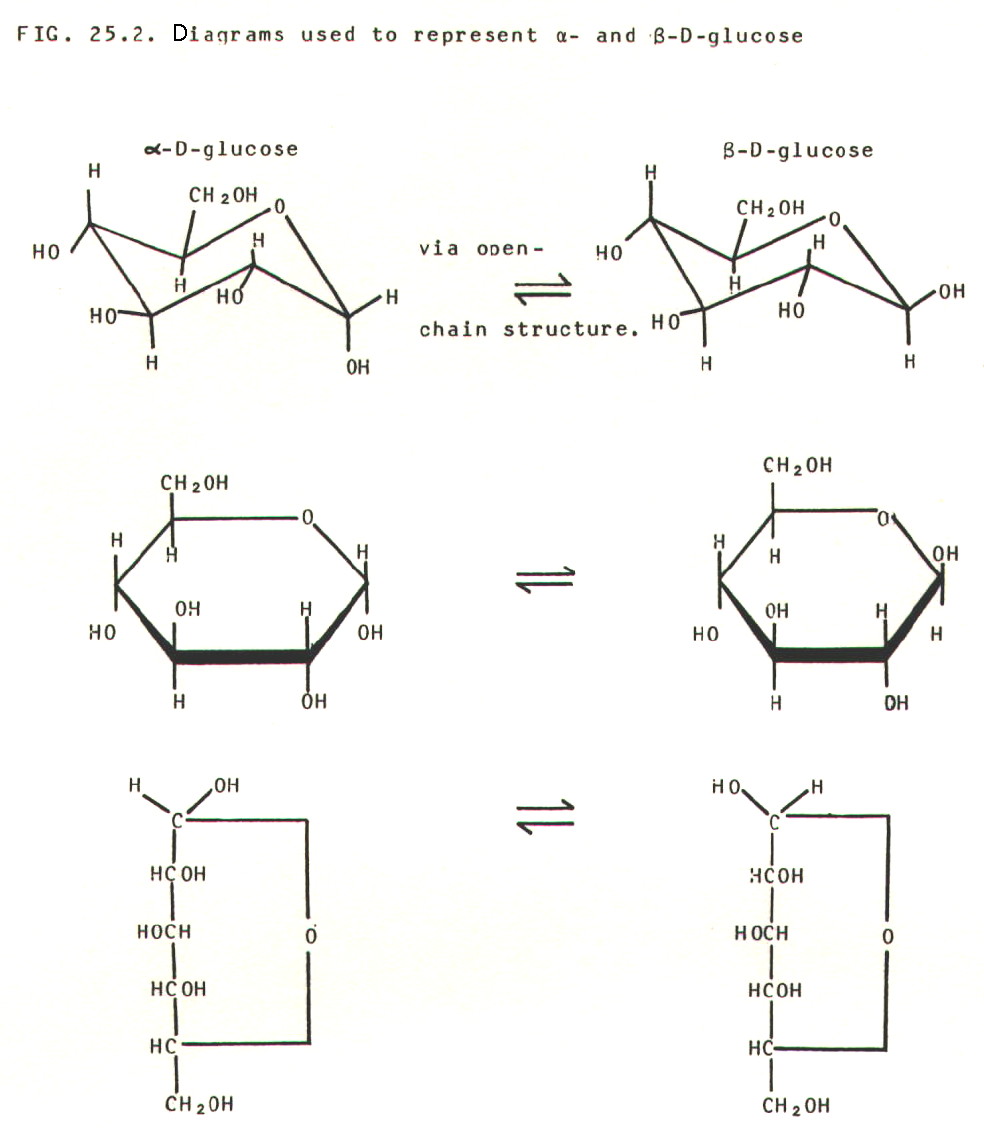
The -
and 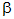 - forms are
interconvertible geometric isomers (section 24.3.2.)
- forms are
interconvertible geometric isomers (section 24.3.2.)
The prefix D refers to the configuration (not to be confused with conformation in section 25.2.5.) of the molecule. D = right-handed and L = left-handed. However, there is no simple relationship between a molecule's configuration and its effect on plane polarised light. Thus the common enantiomers of both glucose and fructose are the D forms, but D-glucose is dextrorotatory, D(+)-glucose, whereas D-fructose is laevorotatory, D(-)-fructose.
Yet further confusion may arise because, in the past, the prefixes d- and l- were used instead of (+)- and (-)-.
Both glucose and fructose are examples of hexoses with general formula C6H12O6. Pentoses, with five carbon atoms, are also common.
25.3.3. A surprising property of glucose is its ability to reduce Fehling's solution and Tollen's solution. This suggests that it has an aldehyde group, which is not apparent from any of the structural diagrams in FIG. 25.2.
The explanation lies in
the fact that the ring structures of both glucose and fructose are in
equilibrium with small concentrations of open-chain structures. The
ring structure is formed from the open-chain structure by an internal hemi-acetal
link (section 22.2.1. and table 22.1.).
Glucose, with its free aldehyde
group in the open-chain structure is known as an aldose.
Its reducing ability also places it in another category: reducing
sugar. Fructose is not a reducing sugar because it has a
ketone group in the open chain-structure rather than an aldehyde group.
It is a ketose. Just to add to this conglomeration
of terminology, glucose is an aldohexose and
fructose is a ketohexose.
Slightly more interestingly, the open chain structure can be seen to have four asymmetric carbon atoms, which are, moreover, all different from each other. Thus each molecule has eight pairs of enantiomers (mirror images). Glucose is one of the aldohexose pairs, and fructose is one of the ketohexose pairs.
i.e. For clarification
only: there are eight aldohexoses: allose, altrose, glucose, mannose,
gulose, idose, galactose, and talose, each of which has a D and an L
enantiomer. For example, the glucose enantiomers are the common one,
D(+)-glucose, and its mirror image, L(-)-glucose. Remember also, there
are - and - isomers of the ring structures!
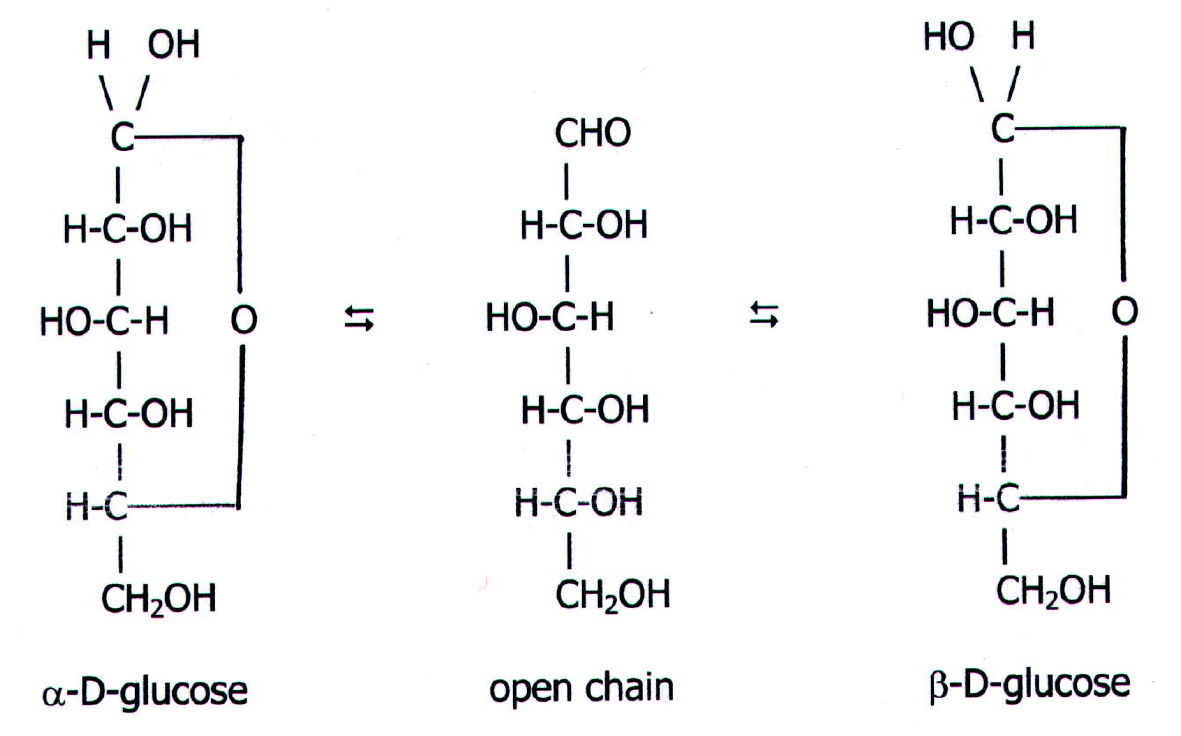
25.3.4. Another
property of monosaccharides is the basis of polysaccharide
synthesis. It is the formation of the glycosidic
link. The reaction, which is similar to hemi-acetal formation, occurs
in living organisms at the active site of an enzyme:
The result is a disaccharide,
in this case maltose. Sucrose is a disaccharide of glucose and
fructose. Adding further monosaccharides onto the chain eventually
gives polysaccharides.
25.3.5. Cellulose and starch are both polysaccharides made up from glucose units.
i) Cellulose
(RMM 20,000 to 500,000) is made up from glucose molecules in which the
glycosidic link is between carbon atom 1 of one glucose unit and carbon
atom 4 of the next. The configuration of the link is - and this produces a molecule
which exists as a zig-zag chain. Cellulose fibres are bundles of
parallel molecules held together by hydrogen bonds.
ii) Starch
consists of two molecular types. The first, amylose
(RMM 9,000 to 90,000), is like cellulose in that the glycosidic link is
C1 to C4. However, the configuration is -
and this produces a molecule which exists as a coil. It is this
component of starch which forms the blue/black complex with iodine.
Iodine molecules lie along the axis of the coil.
The second component of
starch, amylopectin (RMM 50,000 to 10,000,000),
also contains a chain of glucose units linked in the -1,4
pattern, but in addition
there are side chains involving 1,6 and other types of linkage.
25.3.6. Hydrolysis of cellulose and starch may be acheived enzymatically, or by heating with mineral acids. The ultimate product is glucose, except when starch is hydrolysed by the enzyme maltase. This produces the disaccharide, maltose.
The maltose reaction
occurs in the malting process when barley is allowed to germinate in a
warm, moist environment. It is also the first stage in the digestion of
starch in our diet. In contrast, humans do not possess the enzyme
emulsin, which can break -glycosidic
linkages and allow digestion of cellulose. However, the enzyme is
present in herbivores.
Cellulose from the cotton plant is used as a natural fibre in clothing etc. Modified cellulose, the ethanoate ester of cellulose from wood pulp, is the artificial fibre, rayon. An inorganic ester, trinitrocellulose, is the explosive, guncotton.
25.4. NUCLEIC ACIDS
25.4.1. There are two types of nucleic acid in living organisms, DNA and RNA, i.e. deoxyribonucleic acid and ribonucleic acid.
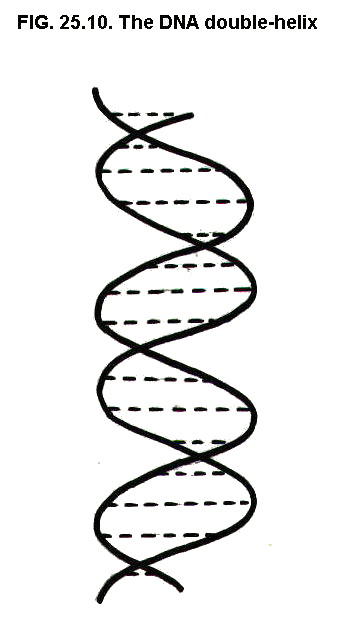
DNA, which exists as the famous two-stranded double helix, occurs in the nucleus of cells and is the material from which genes are made (not to be confused with blue denim).
Messenger RNA (mRNA) acts as a messenger within a living cell by conveying genetic information from the genes in the nucleus, to the protein synthesising machinery (ribosomes) outside the nucleus. Transfer RNA (tRNA) reads the genetic information encoded in the mRNA, translating the particular base sequence of the mRNA (genetic code) into the amino acid sequence of the protein.
RNA is single stranded, though in tRNA part of the strand forms a double helix with itself.
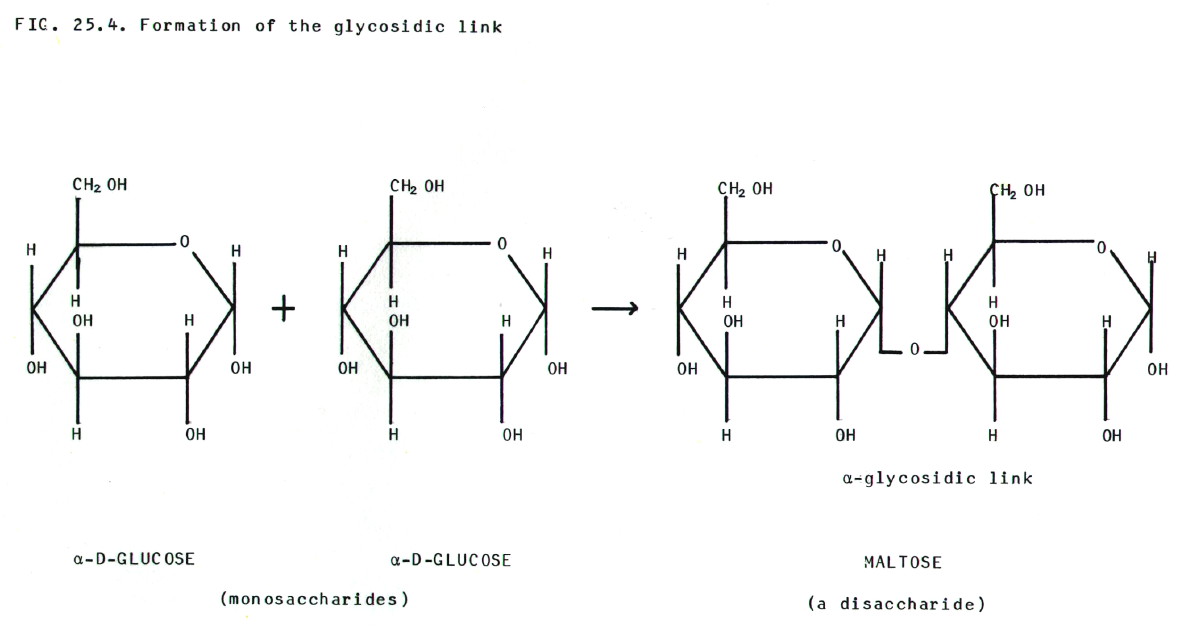
25.4.2. Nucleic
acids are built from three components, nitrogenous bases
(purines and pyrimidines), 5-carbon sugars (pentoses), and phosphate
groups. There are some differences between DNA and RNA which are
summarised in table 25.2.
25.4.3. Nucleosides
comprise a nitrogenous base plus a pentose sugar.
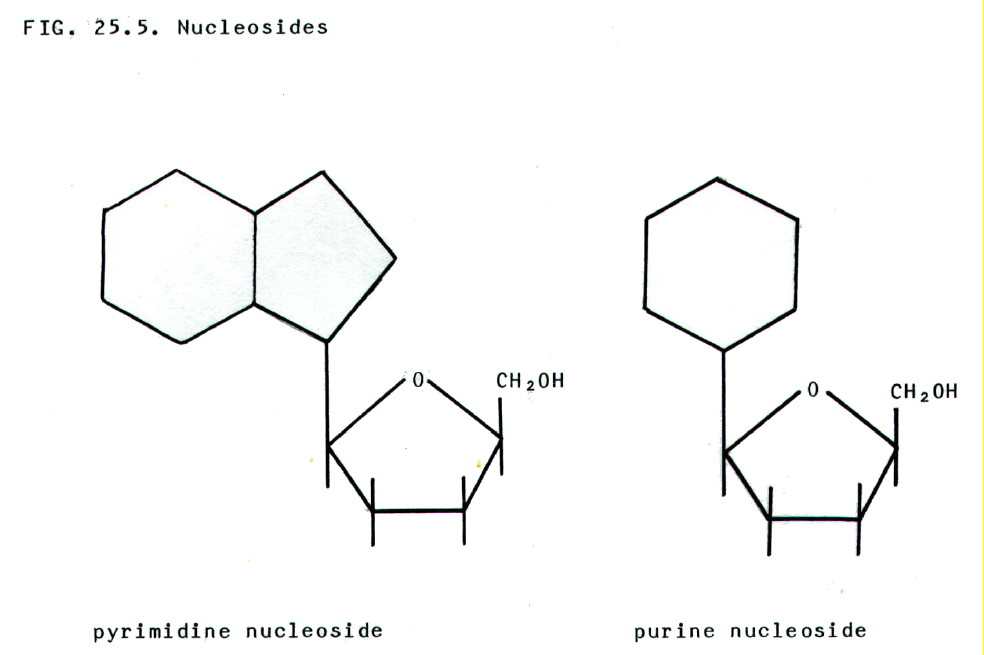
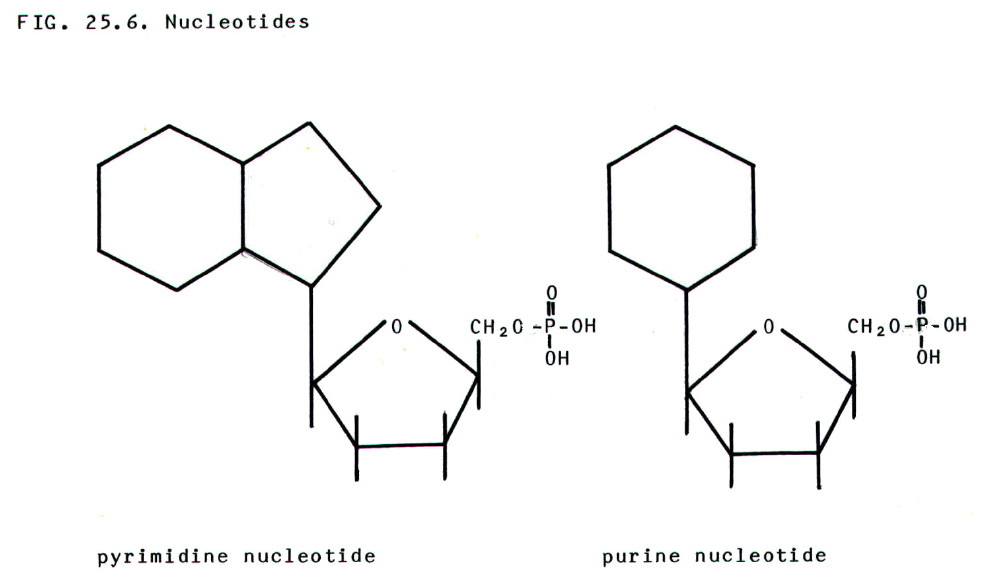
25.4.4. Nucleotides
are phosphate esters of nucleosides.
One particulary special
nucleotide is ATP, adenosine triphosphate. Many
enzymic reactions link hydrolysis of ATP with thermodynamically
unfavourable reactions. 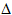 G
for the hydrolysis is negative, making the overall free energy change
for the linked reactions favourable. ATP is therefore described loosely
as an energy source for many reactions in living organisms. Even more
loosely, the bond to the third phosphate group is described as a high
energy bond.
G
for the hydrolysis is negative, making the overall free energy change
for the linked reactions favourable. ATP is therefore described loosely
as an energy source for many reactions in living organisms. Even more
loosely, the bond to the third phosphate group is described as a high
energy bond.
25.4.5. Nucleic acids
may be regarded as polymers of nucleotides.
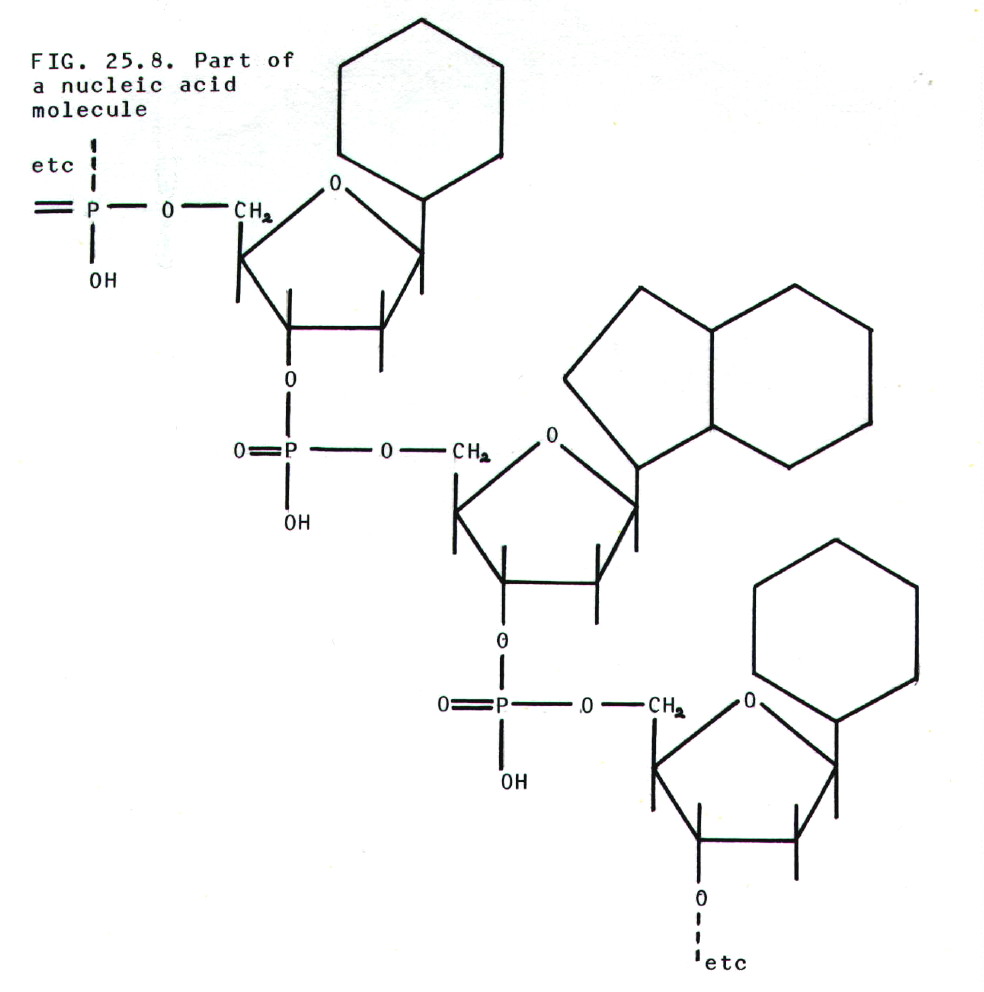
25.4.6. In the DNA
double helix the two strands are held together by hydrogen
bonds between bases. However, the critical point is that, owing to the
positioning of C=O, N-H, and =N groups, only two pairs of bases form
strong hydrogen bonds: thymine/adenine, and cytosine/guanine.
Thus in the DNA double
helix, it is found that one chain is a reverse order copy of the other
i.e. complementary.
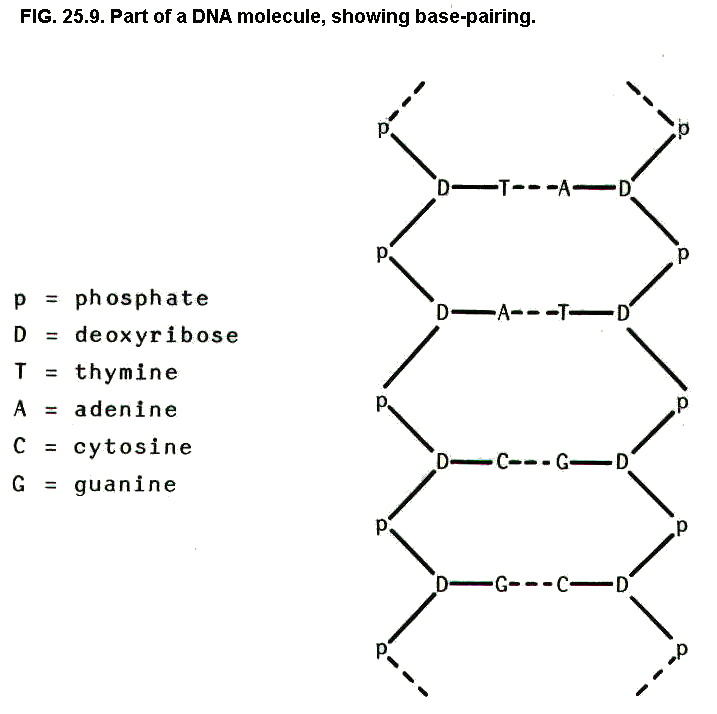
Further bonding holds the
strands in a helix, the double helix:
25.4.7. During
replication of DNA the strands uncoil, starting at one end,
and a complementary strand is built up on each of the existing strands.
Base-pairing ensures the right order of bases, and enzymes link the
nucleotides together. If mistakes do occur, other enzymes chop them out
and yet other enzymes carry out repair work. This results in the
production of two daughter molecules identical to the parent molecule.
25.4.8. Transcribing the DNA to produce mRNA is a similar process to replication. However, only that part of the DNA molecule which makes up a particular gene un-zips, only one strand of mRNA is produced, a different enzyme links the nucleotides, and it is uracil rather than thymine which pairs with adenine.
25.5. PROTEIN SYNTHESIS
When mRNA has been produced, it leaves the nucleus to have its genetic code translated into the amino acid sequence of a protein. This happens in cell organelles known as ribosomes.
tRNA is an essential part of the translation process. tRNA molecules pick up amino acids by bonding with the amino acid carboxyl groups. At the other end of the tRNA helix there is a sequence of 3 bases known as the anticodon.
Each amino acid has one to four specific types of tRNA molecule. Each of these tRNA molecules has a specific anticodon. Thus glycine has four tRNA molecules and is therefore represented by four anticodons: CCA, CCG, CCU, and CCC.
These anticodons pair with specific 3 base sequences on the mRNA known as codons. It follows that tRNA molecules bring amino acid molecules to the mRNA in an order specified by the sequence of codons on the mRNA. Enzymes then link the amino acids to form proteins whose amino acid sequence is determined by this order of mRNA codons.
Since the order of mRNA
codons is, in turn, determined by the base sequence of DNA in a
particular gene, it can be seen how genes control the structure of
proteins.
(Click on diagram to
enlarge on a new web page)
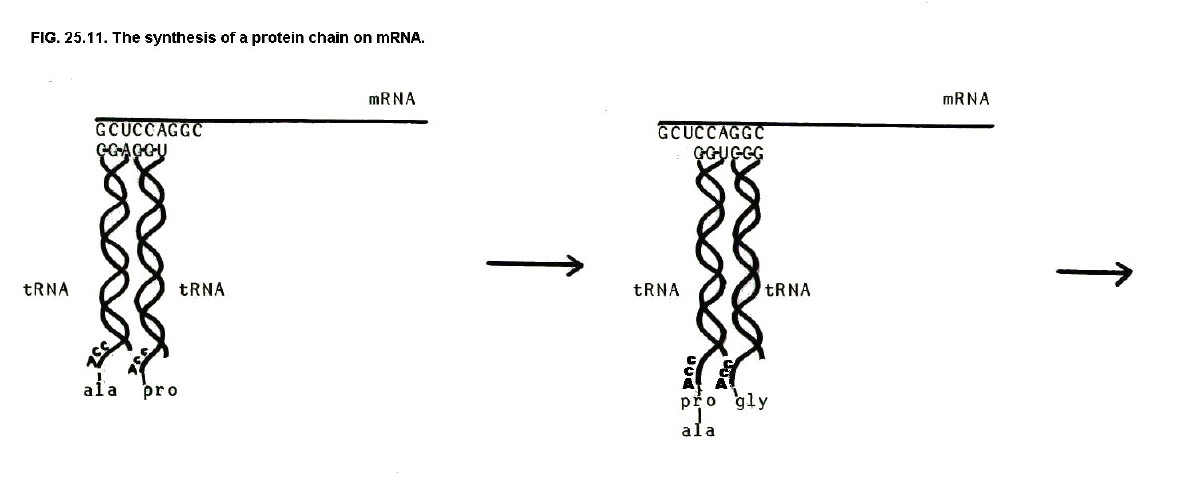
25.8. QUESTIONS
1) Why has the word "neutral" been placed in inverted commas in the last paragraph of section 25.2.3?
2) Show the mechanisms of the reactions used to prepare a-amino acids.
3) Hydrolysis of proteins and polysaccharides may be carried out using enzymes. Why do you think these particular enzymes exist in living organisms?
4) How could the enzymes described in sections 25.2.7.ii. and 25.2.8.ii. be used for determining the amino acid sequence of a protein?
5) Describe how the amino acid sequence of a protein determines its secondary and tertiary structure.
6) At the end of section 24.3.4. it was said that certain bacteria consume only one optical isomer from some pairs of isomers. This formed the basis of a method for isolating one isomer from a racemic mixture of isomers. If you found a bacterium which consumed glycine and glucose, explain which isomers you could isolate from racemic mixtures of each of the two compounds?
6) Using the RMM values in section 25.3.5. calculate the approximate number of glucose units which may be linked together in i) cellulose, ii) amylose, and iii) amylopectin. (RAM C = 12, H = 1, and O = 16.)
Unless otherwise stated, all materials in this web version of chapter
25 are © 2007 Adrian Faiers MA (Oxon) MCIPR

What 's the connection between a dozen eggs and
a garden mole?

Answer: Not a lot, really, but see Chapter 1